

On October 20, 2025, AWS experienced a major outage centered in its US-East-1 region (Northern Virginia), which triggered one of the most sweeping internet disruptions in recent memory. The outage knocked offline a wide array of services—including major apps, consumer platforms, and website infrastructures.
AWS later revealed the root cause: an automation subsystem in its DNS (Domain Name System) management for its DynamoDB service malfunctioned, resulting in many DNS records either being lost or not updated. This disruption prevented clients from locating their data—even though the data itself was intact.

Here’s a closer look at the cascading failure chain:
- DNS Failure in DynamoDB – AWS objects to DynamoDB’s DNS endpoint in US-East-1 failed to resolve due to a latent automation bug.
- Dependent Services Fail – Many AWS services and customer workloads rely on DynamoDB and internal routing. When DNS failed, those dependent services began to misbehave or get locked out.
- EC2 / Instance Availability Impacted – The internal state-management subsystem (DropletWorkflow Manager) for EC2 in that region began timing out leases and flagging capacity incorrectly because it couldn’t update state in DynamoDB.
- Network Manager Congestion – Even after primary services were restored, changes queued and network configuration propagation lagged extensively, delaying full recovery
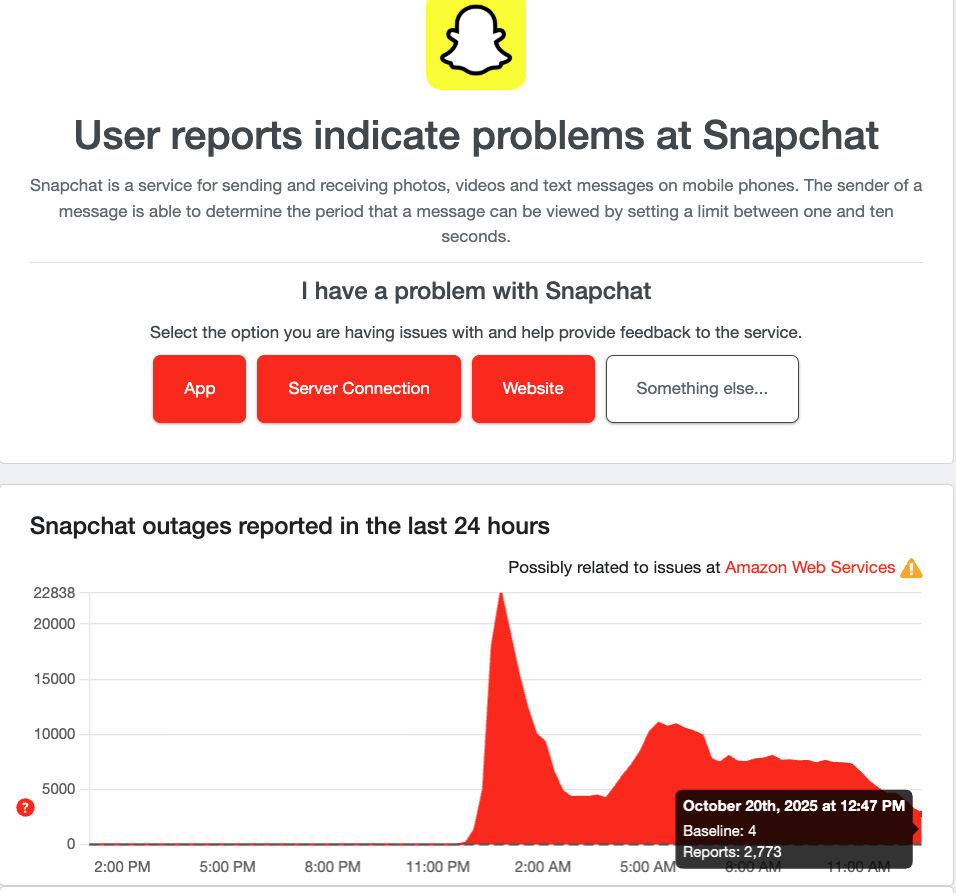
- Global Ripple Effects – Services globally experienced failure or degraded performance—even if they were in other regions—but reliant on things still tied back to US-East-1. Platforms impacted included Venmo, Snapchat, Discord, Roblox, and even smart-home gear like Ring.
Even though AWS is globally redundant, US-East-1 serves as a default region and a heavy-traffic hub. Issues there have outsized effects. The issue wasn’t a malicious cyberattack—it stemmed from automation logic and DNS record management. This illustrates that operational tools and scripts can pose major risk vectors. Many organisations assume multi-region redundancy—but subtle dependencies (APIs, shared services, backend routing) can still create single-points-of-failure.
What You Should Do
- Map Your Cloud Dependencies: Identify which cloud regions, APIs and downstream services your organisation uses—even indirectly.
- Simulate Region Failure: Conduct drills where a key region or service is unavailable—how well do your systems failover?
- Multi-Region / Multi-Cloud Where Needed: For critical services, avoid reliance on a single provider or region.
- Monitor DNS & Internal Services: Often firewalls, APIs and automated tooling are blindspots—monitor changes in DNS resolution, API failures, and automation scripts.
- Communicate Internally: Make sure your executive team understands the risk of cloud provider outages—not just security threats.
The October 2025 AWS outage revealed something fundamental: our digital infrastructure is more fragile than most realise. When one major cloud hub falters, the internet can momentarily stumble. For cybersecurity and IT leaders, the lesson is clear—resilience isn’t optional. It’s essential.
{kind=link}